En el ámbito de la investigación educativa, la relación entre dos o más variables se evalúa mediante una herramienta estadística clave, que incluye la significancia estadística de correlaciones, medido a través del p-valor.
Sin embargo, entre estudiantes de doctorado y, a veces, entre investigadores con experiencia, es común pensar que el coeficiente de Pearson es la única opción válida para medir asociaciones.
Como señala Field (2018), “la elección incorrecta de una medida de asociación puede llevar a interpretaciones erróneas de los datos, comprometiendo la validez de las conclusiones” (p. 203).
Por lo tanto, es esencial considerar no solo la magnitud de la relación, sino también su significancia para obtener conclusiones más robustas y fundamentadas.
Este artículo, inspirado en la infografía de Iris Montalbán (“¿Usas Pearson para todo? Guía rápida para elegir la correlación correcta”), tiene como objetivo desglosar los tipos de correlación disponibles, sus características, cuándo usarlos, y , lo más importante, ejemplos concretos en el contexto educativo.
Además, se abordarán consideraciones metodológicas clave para garantizar rigor en la investigación.
1. Fundamentos Teóricos: ¿Qué es la Correlación?
La correlación, especialmente a través de los tipos de correlación: Pearson y Spearman, cuantifica la fuerza y dirección de las relaciones lineales y no lineales entre dos variables (Cohen et al., 2013).
En este sentido, la relación entre variables continuas y linealidad con Pearson se convierte en un aspecto esencial, ya que el cálculo y significado del coeficiente de correlación de Pearson para relaciones lineales es fundamental.
Este coeficiente mide la relación lineal entre dos conjuntos de datos continuos, arrojando valores que oscilan entre -1 y +1.
Este enfoque específicamente dirigido a relaciones lineales permite una interpretación más clara en contextos donde las variables obedecen a la linealidad.
Por otro lado, es crucial entender la diferencia entre Pearson y Spearman, pues el coeficiente de correlación de Spearman es especialmente útil para evaluar relaciones no lineales y entre datos ordinales, ya que evalúa las relaciones monotónicas entre variables sin la obligación de que esta relación sea lineal, produciendo también valores entre -1 y +1.
Para calcular estas correlaciones, se utilizan herramientas y métodos específicos que permiten obtener estos coeficientes.
Existen tipos de correlación directa e inversa en datos bidimensionales, donde una correlación directa indica que a medida que una variable aumenta, la otra también lo hace, mientras que una correlación inversa sugiere que cuando una variable aumenta, la otra disminuye.
Por otro lado, la definición de correlación nula se refiere a la ausencia de relación entre las variables, y esto se puede visualizar a través de un diagrama de nube de puntos, donde los puntos aparecen distribuidos aleatoriamente sin seguir un patrón definido. Su valor oscila entre -1 y +1, lo que permite identificar si la relación es positiva o negativa.
Comprender las diferencias entre correlación y causalidad es fundamental, ya que una correlación positiva o negativa no implica necesariamente que una variable cause cambios en la otra.
+1 indica una correlación positiva perfecta (a mayor valor en una variable, mayor en la otra).
-1 indica una correlación negativa perfecta (a mayor valor en una variable, menor en la otra).
0 sugiere ausencia de relación lineal.
Sin embargo, es crucial entender que correlación no implica causalidad (Hernández et al., 2014).
Por ejemplo, si en un estudio se encuentra que el tiempo de uso de plataformas digitales (X) y el rendimiento académico (Y) tienen una correlación de r = +0.70, esto no significa que las plataformas causen el buen rendimiento.
Podría deberse a que estudiantes motivados usen más recursos digitales y obtengan mejores notas por otros factores (ej.: horas de estudio, apoyo familiar).
2. Tipos de Correlación: ¿Cuál Elegir y Por Qué?
A continuación, se presentan los principales tipos de correlación, incluidos los tipos de correlación: Kendall, organizados según el tipo de variable (continua, ordinal, nominal, binaria) y su aplicabilidad en educación.
Se enfatiza la selección adecuada de coeficientes según tipo de datos (continuas, ordinales, nominales), lo que es esencial para obtener resultados precisos.
Además, se abordará cómo elegir entre métodos de correlación basados en datos, considerando las diferencias entre los datos ordinales e intervalos, lo que es fundamental para realizar un análisis adecuado.
Cada sección incluye:
Definición y rango.
Interpretación.
Ejemplo en educación.
2.1. Correlaciones para Variables Continuas
2.1.1. Pearson (r)
Tipo de variables: Continua + Continua (relación lineal).
Rango: -1 a +1.
Interpretación:
Mide la relación lineal entre dos variables.
Es sensible a outliers (valores atípicos), por lo que se recomienda analizar la normalidad de los datos previamente (Shapiro-Wilk test).
Amplia aplicación en Análisis de Datos Exploratorio (EDA).
Ejemplo en educación:
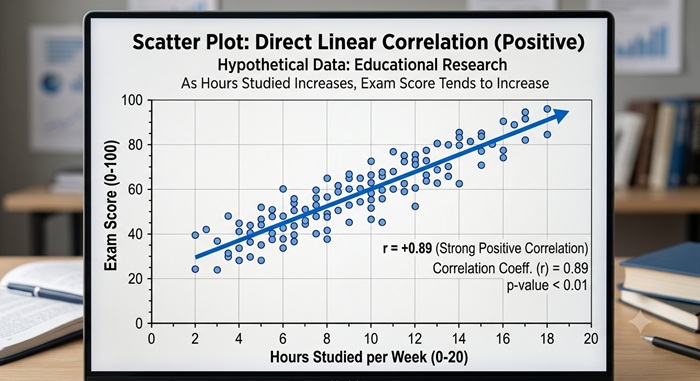
Supongamos que un investigador quiere evaluar si existe relación entre el número de horas de estudio semanales (X) y el promedio de calificaciones (Y) en estudiantes de posgrado. Si los datos son normales y la relación parece lineal (verificada con un diagrama de dispersión), el coeficiente de Pearson sería adecuado. Un resultado de r = +0.85 indicaría que, en promedio, a más horas de estudio, mayor es el rendimiento académico.
Diagrama de Dispersión mostrando correlación directa
Advertencia:
Si la relación es no lineal (ej.: forma de U invertida), Pearson subestimará la asociación. En ese caso, se recomienda usar Spearman o transformar las variables (ej.: logaritmo).
2.1.2. Spearman (ρ)
Tipo de variables: Continua + Continua (o ordinal).
Rango: -1 a +1.
Interpretación:
Basada en rangos (no asume linealidad ni normalidad).
Detecta relaciones monotónicas (crecientes o decrecientes, pero no necesariamente lineales).
Ideal cuando los datos tienen outliers o distribuciones no normales.
Ejemplo en educación:
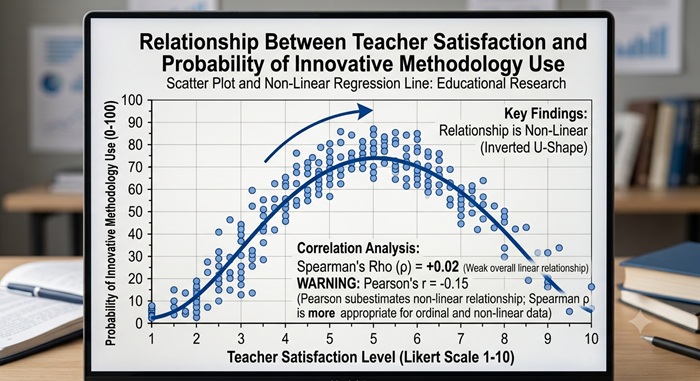
Un estudio analiza la relación entre el nivel de satisfacción docente (medido en una escala Likert de 1 a 10) y la probabilidad de que los profesores usen metodologías innovadoras (escala de 0 a 100). Como las variables son ordinales y podría haber una relación no lineal (ej.: los docentes muy satisfechos y los muy insatisfechos usan menos innovación), Spearman es más apropiado que Pearson.
Ventaja:
Es robusto ante violaciones de los supuestos de Pearson. Según Dancey y Reidy (2020), “Spearman es preferible cuando los datos son ordinales o cuando la normalidad no puede asumirse” (p. 156).
Relación no lineal – Coeficiente de Spearman
2.2. Correlaciones para Variables Ordinales
2.2.1. Kendall (τ)
Tipo de variables: Ordinal + Ordinal (datos con orden).
Rango: -1 a +1.
Interpretación:
Mide la concordancia de pares (número de pares de observaciones que están en el mismo orden vs. los que no lo están).
Ideal para muestras pequeñas (más estable que Spearman en estos casos).
Fácil de interpretar: un τ de +0.60 significa que el 60% de los pares de datos están en el mismo orden.
Ejemplo en educación:
En una investigación sobre clima escolar, se midió el ranking de escuelas (según su infraestructura) y su nivel de retención estudiantil (en una escala ordinal de 1 a 5). Kendall τ sería útil para evaluar si las escuelas con mejor infraestructura también son más efectivas en retener estudiantes.
Diferencia con Spearman:
Kendall es más conservador en la estimación de la correlación, pero más preciso para datos ordinales con pocos valores únicos ( Winter, Gosling & Potter, 2016).
2.2.2. Policórica
Tipo de variables: Ordinal (Likert) + Ordinal (Likert).
Rango: -1 a +1.
Interpretación:
Diseñada específicamente para escalas Likert (ej.: 1 = Totalmente en desacuerdo, 5 = Totalmente de acuerdo).
Asume que las variables ordinales son manifestaciones de variables latentes continuas.
Ejemplo en educación:
Un doctorando investiga la relación entre la satisfacción de los estudiantes (escala Likert de 1 a 5) y su percepción de la calidad de la enseñanza (escala Likert de 1 a 5). La correlación policórica permitiría modelar la relación subyacente entre estas dos variables ordinales.
¿Cuándo usarla?
Cuando ambas variables son ordinales con pocos niveles (ej.: 3 a 7 opciones) y se sospecha que hay una variable continua subyacente.
2.3. Correlaciones para Variables Binarias
2.3.1. Punto-Biserial (r_pb)
Tipo de variables: Binaria + Continua.
Rango: -1 a +1.
Interpretación:
Similar a Pearson, pero una variable es dicotómica (ej.: Sí/No, 0/1).
Útil en A/B testing (ej.: comparar dos grupos).
Ejemplo en educación:
Se quiere evaluar si los estudiantes que aprobaron un curso de metodología de investigación (1 = Sí, 0 = No) tienen un mayor puntaje en su tesis de grado (variable continua). La correlación punto-biserial cuantificaría esta relación.
Relación con la t de Student:
El cuadrado de r_pb es igual al estadístico t de Student para la diferencia de medias entre los dos grupos (Howell, 2012).
2.3.2. Phi (φ)
Tipo de variables: Binaria + Binaria.
Rango: -1 a +1.
Interpretación:
Basada en una tabla de contingencia 2×2.
Mide la asociación entre dos variables dicotómicas.
Ejemplo en educación:
Un estudio analiza si existe relación entre género (1 = Hombre, 0 = Mujer) y aprobación de un examen estandarizado (1 = Aprobó, 0 = No aprobó). Phi sería el coeficiente adecuado.
Limitación:
Si una de las variables tiene más de dos categorías, se debe usar V de Cramer.
2.4. Correlaciones para Variables Nominales
2.4.1. V de Cramer (V)
Tipo de variables: Nominal + Nominal.
Rango: 0 a 1 (no puede ser negativo).
Interpretación:
Extensión de Phi para tablas RxC (donde R y C son el número de categorías de cada variable).
Mide la fuerza de asociación entre dos variables nominales.
Ejemplo en educación:
Se investiga si hay relación entre la región geográfica (Norte, Sur, Este, Oeste) y el canal de atención preferido (Presencial, Virtual, Híbrido) en estudiantes de una universidad. V de Cramer cuantificaría esta asociación.
Interpretación del valor:
0: Independencia total.
1: Asociación perfecta.
Valores intermedios indican grados de asociación (ej.: V = 0.30 sugiere una relación débil).
2.5. Correlación Parcial
Tipo de variables: Cualquiera (controlando una tercera variable).
Rango: -1 a +1.
Interpretación:
Mide la relación entre dos variables controlando el efecto de una tercera.
Aísla el efecto neto de la relación.
Usada en modelado causal y análisis de mediación.
Ejemplo en educación:
Supongamos que queremos evaluar la relación entre horas de estudio (X) y rendimiento académico (Y), pero sospechamos que el nivel socioeconómico (Z) influye en ambas. La correlación parcial entre X y Y, controlando Z, nos diría si las horas de estudio tienen un efecto directo en el rendimiento, independientemente del nivel socioeconómico.
Aplicación en modelos complejos:
Es fundamental en análisis de mediación y moderación (Baron & Kenny, 1986).
3. Aplicaciones Prácticas en Investigación Educativa
A continuación, se presentan casos de estudio adaptados al ámbito educativo:
3.1. Inversión en Recursos vs. Desempeño Estudiantil
Correlación recomendada: Pearson (r).
Contexto:
Una universidad quiere saber si el monto invertido en recursos digitales (libros, software, suscripciones) por estudiante (X) se relaciona con su desempeño en exámenes finales (Y).
Posible hallazgo:
r = +0.65 sugiere que, en promedio, los estudiantes que invierten más en recursos obtienen mejores notas. Sin embargo, esto no implica causalidad: podría ser que estudiantes más motivados inviertan más y estudien más.
3.2. Satisfacción Docente vs. Uso de Metodologías Innovadoras
Correlación recomendada: Spearman (ρ).
Contexto:
Se midió la satisfacción laboral de docentes (escala de 1 a 10) y su frecuencia de uso de metodologías innovadoras (escala de 0 a 10).
Posible hallazgo:
ρ = +0.40 indica una correlación positiva moderada: a mayor satisfacción, mayor uso de innovación.
3.3. Ranking de Escuelas vs. Retención Estudiantil
Correlación recomendada: Kendall (τ).
Contexto:
Se clasifica a las escuelas de una región según su infraestructura (ranking ordinal) y se mide su tasa de retención estudiantil (ordinal: 1 = Muy baja, 5 = Muy alta).
Posible hallazgo:
τ = +0.55 sugiere que las escuelas con mejor infraestructura tienden a tener mayor retención.
3.4. Aprobación de Curso vs. Participación en Talleres
Correlación recomendada: Punto-Biserial (r_pb).
Contexto:
Se quiere saber si los estudiantes que aprobaron un curso de ética académica (1 = Sí, 0 = No) participan más en talleres extracurriculares (horas mensuales).
Posible hallazgo:
r_pb = +0.30 indica que los estudiantes que aprobaron el curso participan, en promedio, 0.3 desviaciones estándar más en talleres.
3.5. Uso de Plataforma Digital vs. Asistencias a Clases
Correlación recomendada: Phi (φ).
Contexto:
Se analiza si existe relación entre el uso de una plataforma digital (1 = Sí, 0 = No) y la asistencia a clases presenciales (1 = Sí, 0 = No).
Posible hallazgo:
φ = -0.20 sugiere una correlación negativa débil: los estudiantes que usan la plataforma tienden a asistir menos a clases presenciales.
3.6. Nivel Educativo vs. Preferencia de Modalidad
Correlación recomendada: V de Cramer (V).
Contexto:
Se investiga si el nivel educativo (Primaria, Secundaria, Universitaria) está asociado con la preferencia de modalidad (Presencial, Virtual, Híbrida).
Posible hallazgo:
V = 0.25 indica una asociación débil pero significativa entre el nivel educativo y la modalidad preferida.
3.7. Satisfacción Estudiantil vs. Percepción de Apoyo Docente
Correlación recomendada: Policórica.
Contexto:
Se mide la satisfacción de los estudiantes (escala Likert de 1 a 5) y su percepción del apoyo docente (escala Likert de 1 a 5).
Posible hallazgo:
Una correlación policórica de +0.70 sugiere una fuerte asociación entre ambas variables.
3.8. Asistencias a Tutorías vs. Inversión en Materiales
Correlación recomendada: Correlación Parcial.
Contexto:
Se quiere evaluar la relación entre asistencias a tutorías (X) y inversión en materiales de estudio (Y), controlando el ingreso familiar (Z).
Posible hallazgo:
La correlación parcial entre X y Y, controlando Z, podría ser r = +0.15, sugiriendo que la relación directa entre tutorías y inversión en materiales es débil una vez que se elimina el efecto del ingreso familiar.
4. Consideraciones Metodológicas Clave
4.1. Supuestos de las Correlaciones
Cada coeficiente de correlación tiene supuestos que deben verificarse antes de su aplicación: la relación entre las variables debe evaluarse con cuidado para elegir la medida adecuada y evitar interpretaciones erróneas, así como también es crucial considerar las limitaciones y sesgos en el análisis de correlación.
En particular, Pearson (r) asume linealidad y normalidad, lo que puede limitar su aplicabilidad en ciertos contextos, especialmente en presencia de outliers.
Por otro lado, el uso de Spearman (ρ) para datos no normales o con outliers permite depender menos de esos supuestos y es útil cuando predominan distribuciones no normales o relaciones monotónicas.
La selección correcta de la medida de correlación mejora la fiabilidad del análisis y la interpretación en contextos educativos, mitigando los sesgos que pueden surgir de una elección inapropiada.
Correlación requiere un análisis profundo, ya que se deben considerar las consideraciones de causalidad y la necesidad de métodos adicionales para validar la relación entre las variables.
Sin estos enfoques complementarios, las conclusiones pueden ser engañosas.
Supuestos
Prueba de Verificación
Pearson (r)
Linealidad, normalidad, homocedasticidad.
Diagrama de dispersión, Shapiro-Wilk.
Spearman (ρ) es útil cuando la relación entre variables es monotónica y cuando no se cumplen los supuestos de linealidad y normalidad.
Se basa en rangos y es robusto frente a outliers, lo que lo hace especialmente adecuado para datos ordinales o con distribuciones no normales. Según Dancey y Reidy (2020), “Spearman es preferible cuando los datos son ordinales o cuando la normalidad no puede asumirse” (p. 156).
Monotonicidad (no linealidad), un concepto fundamental en análisis estadístico, puede ser evaluada utilizando el coeficiente de correlación Kendall Tau para muestras pequeñas, permitiendo así apreciar la relación entre dos variables sin asumir una distribución lineal entre ellas.
Diagrama de dispersión.
La concordancia de pares (τ) se utiliza para medir la relación entre variables ordinales, evaluando cuántos pares de observaciones comparten el mismo orden.
Es especialmente adecuada para muestras pequeñas, ya que ofrece estimaciones más estables que otros métodos en esos casos.
Un valor de τ positivo indica que, en promedio, los pares mantienen el mismo orden entre ambas variables; por ejemplo, un τ de +0.60 implica que el 60% de los pares están en el mismo orden.
4.2. Tamaño de la Muestra
El tamaño de la muestra afecta la significancia estadística de la correlación. Según Cohen (1988), para detectar una correlación moderada (r = 0.30) con un poder estadístico del 80% y α = 0.05, se necesitan al menos 85 observaciones.
Para correlaciones más débiles (r = 0.10), se requieren 783 observaciones.
Recomendación:
En estudios con muestras pequeñas (n < 30), usar Kendall τ o Spearman ρ, ya que son más robustos.
4.3. Interpretación de los Valores
La magnitud de la correlación puede interpretarse selon los criterios de Cohen (1988), donde se destacan las diferencias en la interpretación de correlaciones fuertes vs débiles y su impacto en predicción.
La interpretación de coeficientes de correlación nos ayuda a entender estas relaciones, proporcionando un marco para evaluar la fuerza de la asociación entre variables.
Las correlaciones fuertes suelen indicar relaciones más fiables y predictivas, mientras que las débiles sugieren una menor capacidad para anticipar resultados.
Esta distinción es crucial al analizar datos, ya que influye directamente en la validez de las predicciones que se puedan hacer a partir de las relaciones observadas.
0.00 – 0.19: Correlación muy débil.
0.20 – 0.39: Correlación débil.
0.40 – 0.59: Correlación moderada.
0.60 – 0.79: Correlación fuerte.
0.80 – 1.00: Correlación muy fuerte.
En educación, incluso correlaciones débiles (r = 0.20) pueden ser relevantes si el efecto es consistente y teóricamente fundamentado.
4.4. Visualización de Datos
La visualización es clave para elegir el coeficiente adecuado:
Diagrama de dispersión: Para variables continuas (Pearson, Spearman).
Tabla de contingencia: Para variables nominales o binarias (Phi, V de Cramer).
Gráfico de barras: Para variables ordinales (Kendall, Policórica).
Ejemplo:
Si al graficar horas de estudio vs. rendimiento académico se observa una relación en forma de U invertida (no lineal), Pearson subestimará la asociación. En este caso, Spearman o una regresión polinómica serían más apropiados.
5. Errores Comunes y Cómo Evitarlos
5.1. Usar Pearson para Todo
Error: Asumir que Pearson es el único coeficiente válido.
Solución:
Verificar el tipo de variables (continua, ordinal, nominal, binaria).
Evaluar la linealidad y normalidad de los datos.
5.2. Ignorar los Outliers
Error: No detectar valores atípicos que distorsionan la correlación.
Solución:
Usar diagramas de caja para identificar outliers.
Considerar Spearman o Kendall si hay outliers significativos.
5.3. Confundir Correlación con Causalidad
Error: Afirmar que X causa Y porque están correlacionadas.
Solución:
Realizar análisis de mediación/moderación para explorar relaciones causales.
Usar diseños experimentales (ej.: ensayos controlados aleatorizados) para establecer causalidad.
5.4. No Reportar el Tamaño del Efecto
Error: Solo reportar el p-valor (significancia estadística) sin el valor de la correlación (tamaño del efecto).
Solución: Siempre reportar el coeficiente de correlación (r, ρ, τ, etc.) junto con su intervalo de confianza.
Interpretar el tamaño del efecto (débil, moderado, fuerte).
6. Conclusión
La elección del coeficiente de correlación adecuado es un paso crítico en la investigación educativa.
Como se ha visto, Pearson no es siempre la mejor opción: su uso inapropiado puede llevar a interpretaciones erróneas o a la pérdida de información valiosa.
Los estudiantes de doctorado deben familiarizarse con las alternativas disponibles (Spearman, Kendall, Punto-Biserial, etc.) y sus aplicaciones específicas, especialmente en contextos donde los datos no cumplen con los supuestos de Pearson.
Además, es fundamental complementar el análisis correlacional con otras técnicas estadísticas (regresión, análisis de mediación) y, sobre todo, con una interpretación teórica sólida.
Como señala Kerlinger (1986), “la estadística es una herramienta, no un sustituto del pensamiento crítico” (p. 42).
En resumen, la curación de datos en investigación educativa requiere:
Rigor metodológico en la selección del coeficiente.
Transparencia en el reporte de resultados.
Contexto teórico para interpretar los hallazgos.
Solo así podremos avanzar hacia una investigación educativa más robusta y aplicable.
Referencias
Baron, R. M., & Kenny, D. A. (1986). The moderator, mediator variable distinction in social psychological research: Conceptual, strategic, and statistical considerations. Journal of Personality and Social Psychology, 51(6), 1173, 1182. https://doi.org/10.1037/0022-3514.51.6.1173
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Lawrence Erlbaum Associates.
Cohen, L., Manion, L., & Morrison, K. (2013). Research methods in education (7th ed.). Routledge.
Dancey, C. P., & Reidy, J. (2020). Statistics without maths for psychology: Using SPSS for Windows (8th ed.). Pearson.
Field, A. (2018). Discovering statistics using IBM SPSS Statistics (5th ed.). Sage.
Hernández, R., Fernández, C., & Baptista, P. (2014). Metodología de la investigación (6th ed.). McGraw-Hill.
Howell, D. C. (2012). Statistical methods for psychology (8th ed.). Cengage Learning.
Kerlinger, F. N. (1986). Foundations of behavioral research (3rd ed.). Holt, Rinehart & Winston.
Winter, J. de, Gosling, S. D., & Potter, J. (2016). Comparing the Pearson and Spearman correlation coefficients across distributions and sample sizes: A tutorial using simulations and empirical data. Psychological Methods, 21(3), 273, 290. https://doi.org/10.1037/met0000079
Tesis de Cero a 100, El Diseño 🧐No vas a querer perderte este curso online!
Hola Doctor...
Suena bien, ¿no? Podrás obtener tu título de Doctor o Magister más rápido con nuestro curso de cinco estrellas Tesis de Cero a 100, El Diseño. Aprende todo lo que el supervisor debería haberte enseñado sobre la planificación de una tesis de doctorado o maestría. Ahora a precios reducidos. Únete a cientos de otros estudiantes y conviértete en un mejor investigador.